Compilation#
One of PyTorch main strengths is its flexibility and ease of use. The user can write a model with almost no restrictions as long as each operator is differentiable and PyTorch will take care of the rest. On each forward pass, it will evaluate the operators on-the-fly and dynamically construct the computation graph, which is then used to compute the gradients during the backward pass. This is called Eager execution mode and it is the default behavior of PyTorch.
This mode comes in handy when the computation graph is not static, for example when the model has if-statements or loops that depend on the input data or when the input has dynamic shapes (imagine training a model with multiple resolutions). However, this flexibility comes at a cost, because we can’t optimize a model if we don’t know what operations, which shapes, types or even order of operations will be executed until runtime. This is where compilers come in.
Compilers 101#
A compiler is a program that translates instructions written in one representation (source) into another representation (target). Nowadays, compilers usually are separated in a frontend and a backend. The frontend is responsible for parsing the source code and generating an intermediate representation (IR) that is independent of the source language. The backend is responsible for translating the IR into the target language. This separation allows for reusability of the frontend with different backends, and vice versa as we can see in Figure 13.
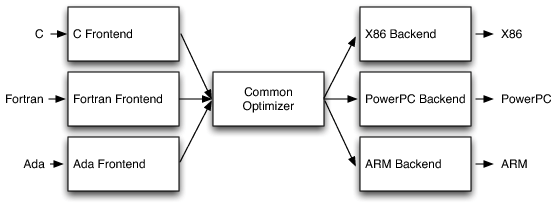
Fig. 13 Frontends produce an intermediate representation (IR) common to all backends. Backends take the IR and generate code for a specific target. [BW12]#
So far, we’ve talked about compilation as a process that happens before the program is executed, also known as ahead-of-time (AOT) compilation. However, there are other ways to execute a program. Some languages, like Python, are interpreted, where programs are executed line by line by the runtime interpreter. Furthermore, some runtimes might use just-in-time (JIT) compilation, where parts of the program are compiled while it is being executed. This allows for optimizations that can only be done at runtime, like specializing code for specific inputs.
ML Compilers#
Machine learning compilers take a model written in some framework (e.g. PyTorch), translate it into a program that can be executed in some runtime (e.g. TensorRT, CoreML, PyTorch TorchInductor) which then ends up optimized for some specialized hardware (e.g. GPUs, TPUs, Apple Silicon).
PyTorch has had a few different compiler solutions over the years, the most popular being TorchScript. This, however, has changed since PyTorch 2, as the new compiler stack has been introduced. The main component of this new stack is TorchDynamo, a new compiler frontend with better properties and more Python support than TorchScript.
Along with TorchDynamo, PyTorch 2 has introduced two new APIs, torch.export and torch.compile, that leverage this technology. On one hand, torch.export’s goal is to act as an ahead-of-time frontend which captures the full semantics of the program into an IR independent of Python, while torch.compile is meant to be used as a full JIT compiler that can leverage other backends (TorchInductor, TensorRT, ONNX) to optimize parts of the model at runtime and fallback to native Python if necessary.
For edge devices specifically, we are most interested in the torch.export API, as it allows us to dispose of the expensive overhead of the Python Runtime and allows us to take advantage of native optimized frameworks for our target hardware, like CoreML for Apple devices or TensorRT (C++) for NVIDIA GPUs.
For convenience, we’ll use the popular abbreviation of PyTorch 2 Export, PT2E.
PT2E 101#
The main idea of torch.export is that it translates an Eager Mode PyTorch model into a graph-based intermediate representation called Export IR. This allows compiler backends to take this IR and further transform and optimize it for a target device. A general overview of the process is shown in the figure below.
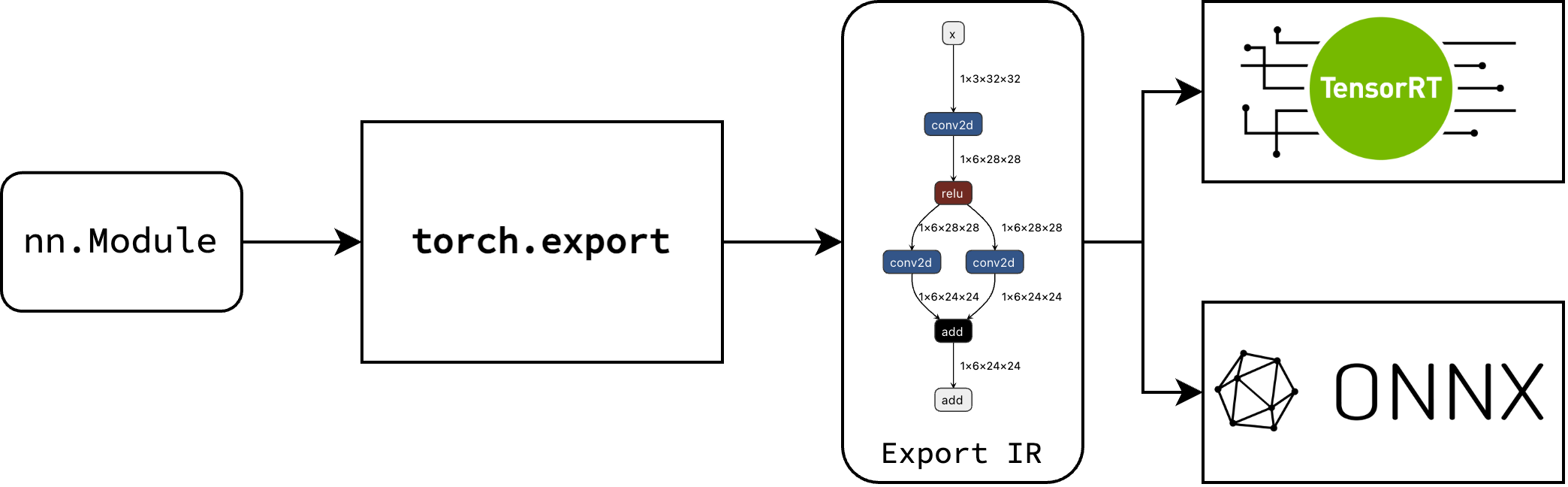
Fig. 14 PyTorch 2 Export#
This IR needs to fulfill a couple of properties for it to be useful to compilers. For example:
Operators have to be general enough for backends to notice patterns and optimize them: Many runtimes have specialized kernels for common operators like convolutions or even more complex ones like a
conv2 + relu(operator fusion, see examples here). If the IR reduces all operators to sums, products and views, noticing these patterns becomes too hard.The number of operators has to be small enough for the backend to implement all of them.
Operators have to be functional, that is, without side effects. For example: If two functions read and modify the same parameters, the order of execution matters and the compiler has to be careful when parallelizing them.
Notice that properties 1 and 2 are in conflict with each other. The more operators we have, the more expressive the IR is, but the harder it is to implement all of them. This is a trade-off that the PyTorch team has to balance.
For now, let’s get some practical intuition with an example.
Hands on with PT2E#
Let’s use a simple network to see how torch.export works.
Show code cell source
import torch
import pprint
from part3_artifacts.simple_net import SimpleNet
import torch.fx.graph_module
from myst_nb import glue
Show code cell source
SimpleNet??
Init signature: SimpleNet()
Source:
class SimpleNet(nn.Module):
"""
Just a simple network
"""
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(3, 6, 5)
self.fc = nn.Linear(4704, 10)
def forward(self, x: torch.Tensor):
z = self.conv1(x)
z = F.relu(z)
y = self.conv2(x)
y = F.relu(y)
o = z + y
o = torch.flatten(o, 1)
o = self.fc(o)
return o
File: ~/development/amsterdam/edge/docs/src/part3/part3_artifacts/simple_net.py
Type: type
Subclasses:
To export a model we must first define a sample input. This is used to trace the model and generate the Export IR.
Note
Tracing refers to the process of recording the operations executed by a model when given a specific input along with their metadata.
The way tracing works efficiently is by using torch._subclasses.fake_tensor.FakeTensor. FakeTensors are a special type of tensor that only store metadata such as dtype, shape and device and overload all operators to simulate the computation without actually looking at the values.
For example, doing matrix multiplications of FakeTensors of shapes (N, M) and (M, K) will return a FakeTensor of shape (N, K) in constant time instead of the normal cubic complexity of multiplication.
For our case, the model will be deployed on a camera with a fixed resolution, so we can just define a statically shaped tensor of batch_size 1. If you want to support dynamically shaped inputs, refer to the documentation.
Once we have the input, we can call the torch.export.export function.
x = torch.randn(1, 3, 32, 32)
ep: torch.export.ExportedProgram = torch.export.export(SimpleNet().eval(), (x,))
And that’s it, we have exported our model. The new object is a torch.export.ExportedProgram which contains the model and parameters in the Export IR. Let’s inspect it one by one.
The first and most important attribute is the graph_module which stores the computational graph of the model. We can print it using the print_readable method:
graph_module: torch.fx.GraphModule = ep.graph_module
print(graph_module.print_readable(print_output=False, colored=True, include_device=True))
class GraphModule(torch.nn.Module):
def forward(self, p_conv1_weight: "f32[6, 3, 5, 5]cpu", p_conv1_bias: "f32[6]cpu", p_conv2_weight: "f32[6, 3, 5, 5]cpu", p_conv2_bias: "f32[6]cpu", p_fc_weight: "f32[10, 4704]cpu", p_fc_bias: "f32[10]cpu", x: "f32[1, 3, 32, 32]cpu"):
# File: /home/dgcnz/development/amsterdam/edge/docs/src/part3/part3_artifacts/simple_net.py:16 in forward, code: z = self.conv1(x)
conv2d: "f32[1, 6, 28, 28]cpu" = torch.ops.aten.conv2d.default(x, p_conv1_weight, p_conv1_bias); p_conv1_weight = p_conv1_bias = None
# File: /home/dgcnz/development/amsterdam/edge/docs/src/part3/part3_artifacts/simple_net.py:17 in forward, code: z = F.relu(z)
relu: "f32[1, 6, 28, 28]cpu" = torch.ops.aten.relu.default(conv2d); conv2d = None
# File: /home/dgcnz/development/amsterdam/edge/docs/src/part3/part3_artifacts/simple_net.py:18 in forward, code: y = self.conv2(x)
conv2d_1: "f32[1, 6, 28, 28]cpu" = torch.ops.aten.conv2d.default(x, p_conv2_weight, p_conv2_bias); x = p_conv2_weight = p_conv2_bias = None
# File: /home/dgcnz/development/amsterdam/edge/docs/src/part3/part3_artifacts/simple_net.py:19 in forward, code: y = F.relu(y)
relu_1: "f32[1, 6, 28, 28]cpu" = torch.ops.aten.relu.default(conv2d_1); conv2d_1 = None
# File: /home/dgcnz/development/amsterdam/edge/docs/src/part3/part3_artifacts/simple_net.py:20 in forward, code: o = z + y
add: "f32[1, 6, 28, 28]cpu" = torch.ops.aten.add.Tensor(relu, relu_1); relu = relu_1 = None
# File: /home/dgcnz/development/amsterdam/edge/docs/src/part3/part3_artifacts/simple_net.py:21 in forward, code: o = torch.flatten(o, 1)
view: "f32[1, 4704]cpu" = torch.ops.aten.view.default(add, [1, 4704]); add = None
# File: /home/dgcnz/development/amsterdam/edge/docs/src/part3/part3_artifacts/simple_net.py:22 in forward, code: o = self.fc(o)
linear: "f32[1, 10]cpu" = torch.ops.aten.linear.default(view, p_fc_weight, p_fc_bias); view = p_fc_weight = p_fc_bias = None
return (linear,)
Here we can see all nodes (conv2d, relu, conv2d_1, etc.), their shapes, dtypes, devices and the aten operators that are being used (torch.ops.aten.conv2d.default), with their accompanying file, line and code. We can also see that the graph inputs expects not only the model inputs but also its parameters (buffers and constants too).
Note
A torch.fx.GraphModule is just a wrapper around its fx.Graph, and you can access it through graph_module.graph. This is useful for two reasons:
Most of the compiler steps will work with
fx.Graphdirectly, so it’s good to get acquainted with its attributes in case you need to debug an error.You might need to manipulate the graph directly to ensure compatibility (example).
To start, if we want to print the underlying graph, we can do it like this:
print(str(graph_module.graph))
graph():
%p_conv1_weight : [num_users=1] = placeholder[target=p_conv1_weight]
%p_conv1_bias : [num_users=1] = placeholder[target=p_conv1_bias]
%p_conv2_weight : [num_users=1] = placeholder[target=p_conv2_weight]
%p_conv2_bias : [num_users=1] = placeholder[target=p_conv2_bias]
%p_fc_weight : [num_users=1] = placeholder[target=p_fc_weight]
%p_fc_bias : [num_users=1] = placeholder[target=p_fc_bias]
%x : [num_users=2] = placeholder[target=x]
%conv2d : [num_users=1] = call_function[target=torch.ops.aten.conv2d.default](args = (%x, %p_conv1_weight, %p_conv1_bias), kwargs = {})
%relu : [num_users=1] = call_function[target=torch.ops.aten.relu.default](args = (%conv2d,), kwargs = {})
%conv2d_1 : [num_users=1] = call_function[target=torch.ops.aten.conv2d.default](args = (%x, %p_conv2_weight, %p_conv2_bias), kwargs = {})
%relu_1 : [num_users=1] = call_function[target=torch.ops.aten.relu.default](args = (%conv2d_1,), kwargs = {})
%add : [num_users=1] = call_function[target=torch.ops.aten.add.Tensor](args = (%relu, %relu_1), kwargs = {})
%view : [num_users=1] = call_function[target=torch.ops.aten.view.default](args = (%add, [1, 4704]), kwargs = {})
%linear : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%view, %p_fc_weight, %p_fc_bias), kwargs = {})
return (linear,)
This is similar enough to the graph_module’s output, so let’s move on. Each “variable” in the graph is a Node object, and we can access them like this:
print(list(graph_module.graph.nodes))
[p_conv1_weight,
p_conv1_bias,
p_conv2_weight,
p_conv2_bias,
p_fc_weight,
p_fc_bias,
x,
conv2d,
relu,
conv2d_1,
relu_1,
add,
view,
linear,
output]
Specifically, if we’re interested in a particular node, like the relu_1 node, we can filter it by name:
relu_1 = next(filter(lambda n: n.name == "relu_1", graph_module.graph.nodes))
Some of its most important attributes are the name, op, args, stack_trace, target and users. Let’s print them and see what they store.
The name is just the unique name of the node:
print(relu_1.name)
'relu_1'
The op is the operator that the node represents. It refers to the high-level function that specifies the type of node. It is accompanied by a target and together they define the behavior of the node.
For example Node(op=placeholder, target=p_p_conv1_weight) means that the node is a placeholder for the weight of the first convolutional layer. Inputs, weights, etc are tagged as placeholder nodes.
On the other hand, call_function nodes represent a function call to their target. For example, Node(op=call_function, target=torch.ops.aten.relu.default) means that the node is a call to the relu function, as we can see next:
print(relu_1.op)
'call_function'
print(relu_1.target)
<OpOverload(op='aten.relu', overload='default')>
As we can see, operator is almost used interchangeably with function in this context.
The args are the arguments of the node’s function. In our case, since relu_1 takes as input the output of conv2d_1, we should see a reference to that node.
print(relu_1.args)
(conv2d_1,)
Similarly, the users are the nodes that take the output of relu_1 as input. Both of these attributes are useful to traverse the graph and understand the dependencies between nodes.
print(relu_1.users)
[add]
Finally, the stack_trace is the piece of code that generated the node. This is also useful for debugging and it helps with localizing the source code that should be rewritten in case of an error.
print(relu_1.stack_trace)
File "/home/dgcnz/development/amsterdam/edge/docs/src/part3/part3_artifacts/simple_net.py", line 19, in forward
y = F.relu(y)
For more information refer to the documentation.
Back to the ExportedProgram, the second most important attribute is its graph_signature. This object contains information about the inputs (actual inputs, parameters, constant tensors, etc) and outputs of the model. This is particularly useful if you want to check whether a tensor is being folded as a constant.
We can print it like this:
pprint.pp(ep._graph_signature) # you can also just use print
ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>,
arg=TensorArgument(name='p_conv1_weight'),
target='conv1.weight',
persistent=None),
InputSpec(kind=<InputKind.PARAMETER: 2>,
arg=TensorArgument(name='p_conv1_bias'),
target='conv1.bias',
persistent=None),
InputSpec(kind=<InputKind.PARAMETER: 2>,
arg=TensorArgument(name='p_conv2_weight'),
target='conv2.weight',
persistent=None),
InputSpec(kind=<InputKind.PARAMETER: 2>,
arg=TensorArgument(name='p_conv2_bias'),
target='conv2.bias',
persistent=None),
InputSpec(kind=<InputKind.PARAMETER: 2>,
arg=TensorArgument(name='p_fc_weight'),
target='fc.weight',
persistent=None),
InputSpec(kind=<InputKind.PARAMETER: 2>,
arg=TensorArgument(name='p_fc_bias'),
target='fc.bias',
persistent=None),
InputSpec(kind=<InputKind.USER_INPUT: 1>,
arg=TensorArgument(name='x'),
target=None,
persistent=None)],
output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>,
arg=TensorArgument(name='linear'),
target=None)])
If you want to access the parameters and buffers directly, you can reference the state_dict attribute.
ep._state_dict.keys()
dict_keys(['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'fc.weight', 'fc.bias'])
Constants are tensors that during the forward pass are found to not change (think of a tensor that contains the shape of the input). It is a bit less common to find them, but somestimes ensuring they are constant can help the compiler to parse the model correctly. Our simple network doesn’t have any constants, but you can access them like this:
print(ep.constants)
{}
Finally, we can save our exported program using the torch.export.save function.
torch.export.save(ep, "simple_net.pt2")
Compiling the model#
Before compilation, make sure you have followed the instructions at Downloading trained model (for compilation and evaluation).
The main script to compile our model with the TensorRT backend is scripts.export_tensorrt.
The easiest way to specify a compilation target, is by adding a config file at scripts/config/export_tensorrt. For example, if we want to compile our model, we can use the config file located at scripts/config/export_tensorrt/dinov2.yaml as follows:
python -m scripts.export_tensorrt --config-name dinov2
Recommendations for the following parameters in the config file are given in italics:
image: The sample image’s file path, height and width.Set to target camera dimensions.
amp_dtype:fp16orbf16fortorch.amp.autocastusage,fp32to disable.Set to
fp32and usetrt.enabled_precisions.
trt: The kwargs to overridetorch_tensorrt.dynamo.compile.Set
enabled_precisionstofp32,fp16and if new GPU (Ampere or newer) tobf16.Set
require_full_compilation=Falseif necessary. If possible rewrite the code to remove unsupported nodes because making partial compilation work is harder and error prone.Set
use_fast_partitioner=Falseif partitioner bugs appear, doesn’t usually solve anything but sometimes helps with error diagnosis.Set
enable_experimental_decompositions=Falseif unsupported nodes appear, doesn’t solve much but sometimes helps with error diagnosis.
model: The path to the model’s config file, it’s checkpoints and argument overrides.Try to specialize the model as much as possible. For example, for
timmViTs, disable dynamic image sizes/padding and fix the image_size to your camera’s dimensions.
As an example, here’s the config file for our model.
Show code cell source
%pycat scripts/config/export_tensorrt/dinov2.yaml
image:
height: 512
width: 512
path: "artifacts/idea_raw.jpg"
amp_dtype: "fp32"
trt:
enabled_precisions:
- "fp32"
- "fp16"
- "bf16"
model:
config: "projects/dino_dinov2/configs/models/dino_dinov2.py"
ckpt_path: "artifacts/model_final.pth"
opts:
- "model.backbone.net.img_size=[512, 512]"
- "model.backbone.net.dynamic_img_size=False"
- "model.backbone.net.dynamic_img_pad=False"
- "model.transformer.specialize_with_list=True"
env:
"torch._subclasses.fake_tensor.CONSTANT_NUMEL_LIMIT": 2000
"detrex.layers.multi_scale_deform_attn._ENABLE_CUDA_MSDA": False
You can also override any of these parameters using the command line. For example, to compile the model with torch.amp’s fp16 precision and TensorRT’s fp32, fp16 and bf16 precisions, you can run:
python -m scripts.export_tensorrt --config-name dinov2 amp_dtype=fp16 trt.enabled_precisions="[fp32, bf16, fp16]"
At the end of the compilation process, you should see a message indicating the output directory:
OUTPUT DIR: outputs/2024-10-31/10-43-31
This output directory will contain the following files:
├── export_tensorrt.log # log file (useful for debugging process)
├── .hydra
│ ├── config.yaml # config file (useful for remembering the parameters used)
│ ├── hydra.yaml
│ └── overrides.yaml
├── model.ts # compiled torchscript model
└── predictions.png # sample predictions for the model (visual check that the model is working)
Although this script is a useful entrypoint, the challenge when compiling a model lies in making the models’ source code compatible with both TorchDynamo and the backend of choice (TensorRT in this case). This is a bit harder to explain because during the debugging procedure, you’ll attempt many possible fixes that are informed by insights of the codebase’s state at that time, many of which will be deemed unsuccessful or unnecessary. For example, you might find a way to solve a bug which will itself be fixed by another more important bug. Furthermore, one bug might appear/disappear with newer versions of the libraries.
Because of this, I’ll cover two apparently similar but very different case studies and share some of the relevant insights and tricks in the following two sections:
DinoV2 + ViTDet + DINO: Successful compilation, minimal final rewrites.
ViT + ViTDet + Cascade Mask RCNN: Almost successful, many final rewrites.
To follow the thought process in a single notebook, we’ve added flags throughout the model’s source code to activate or deactivate the most important fixes. To see all the changes, you can check all the differences between my forks of detectron2, detrex and the original repositories.
CS1: Compiling DinoV2+ViTDet+DINO#
Let’s start from where we left off at Adapting the Encoder
Show code cell source
import torch
from omegaconf import OmegaConf
from detrex.modeling.backbone import TimmBackbone
from detectron2.config import LazyConfig, instantiate, LazyCall
import detectron2
import torch_tensorrt
from src.utils import TracingAdapter, load_input_fixed
import detrex
import warnings
import logging
logging.basicConfig(level=logging.ERROR)
cfg = LazyConfig.load("projects/dino_dinov2/configs/models/dino_dinov2.py")
cfg.model.backbone.net = LazyCall(TimmBackbone)(
model_name="vit_base_patch14_dinov2.lvd142m",
features_only=True,
out_indices=(-1,),
patch_size=16,
)
model = instantiate(OmegaConf.to_object(cfg.model))
Before trying anything we must make three small changes from the original code at Adapting the Encoder:
For convenience, we’ll deactivate the custom CUDA multi scale deformable attention kernel and opt for the python implementation. Although you could technically register a custom operator with PT2E compatibility, it’s not worth the effort because of the constant tensor specialization issue we’ll face later and the fact that TensorRT can optimize the python implementation well enough.
Instead of using a random input, use a sample image and resize it to the appropriate dimensions. This might seem like an innocuous change, but if there is some data-dependent computation (for example, some filtering based on the values of the features), then the
torch.exportwill fail but it will show uninformative error logs and guide you erroneously to fix bugs that are not relevant to the real inputs.Export the model with the appropriate device (
cuda) and forward type (eval,torch.no_grad). This is important because sometimes, some operators might decide to use one implementation based on the device of the tensor and some operators are only supported without autograd.
detrex.layers.multi_scale_deform_attn._ENABLE_CUDA_MSDA = False
img, inputs = load_input_fixed(height=518, width=518, device="cuda")
model = model.eval().cuda()
Let’s try to export the model.
try:
with torch.no_grad():
ep = torch.export.export(model, inputs)
except Exception as e:
logging.error(e)
W1030 15:39:20.764723 23824 site-packages/torch/fx/experimental/symbolic_shapes.py:6047] [1/0] failed during evaluate_expr(u0, hint=None, size_oblivious=False, forcing_spec=False
E1030 15:39:20.765498 23824 site-packages/torch/fx/experimental/recording.py:298] [1/0] failed while running evaluate_expr(*(u0, None), **{'fx_node': False})
ERROR:root:Could not extract specialized integer from data-dependent expression u0 (unhinted: u0). (Size-like symbols: none)
Caused by: torch.linspace(0.5, H - 0.5, H, dtype=torch.float32, device=device), # development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino_transformer.py:373 in get_reference_points (_dynamo/utils.py:2260 in run_node)
For more information, run with TORCH_LOGS="dynamic"
For extended logs when we create symbols, also add TORCHDYNAMO_EXTENDED_DEBUG_CREATE_SYMBOL="u0"
If you suspect the guard was triggered from C++, add TORCHDYNAMO_EXTENDED_DEBUG_CPP=1
For more debugging help, see https://docs.google.com/document/d/1HSuTTVvYH1pTew89Rtpeu84Ht3nQEFTYhAX3Ypa_xJs/edit?usp=sharing
User Stack (most recent call last):
(snipped, see stack below for prefix)
File "/home/dgcnz/development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino.py", line 284, in forward
) = self.transformer(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/home/dgcnz/development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino_transformer.py", line 439, in forward
reference_points = self.get_reference_points(
File "/home/dgcnz/development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino_transformer.py", line 373, in get_reference_points
torch.linspace(0.5, H - 0.5, H, dtype=torch.float32, device=device),
For C++ stack trace, run with TORCHDYNAMO_EXTENDED_DEBUG_CPP=1
For more information about this error, see: https://pytorch.org/docs/main/generated/exportdb/index.html#constrain-as-size-example
from user code:
File "/home/dgcnz/development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino.py", line 284, in forward
) = self.transformer(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/home/dgcnz/development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino_transformer.py", line 439, in forward
reference_points = self.get_reference_points(
File "/home/dgcnz/development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino_transformer.py", line 373, in get_reference_points
torch.linspace(0.5, H - 0.5, H, dtype=torch.float32, device=device),
Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information
Oh no, we’ve stumbled into a data-dependent expression error. These errors occur because PT2E currently doesn’t support data-dependent expressions out of the box (check docs). Luckily, this case specifically doesn’t really contain a data-dependent expression, it’s only a compiler bug.
By looking at the code, we can find out that linspace is creating a tensor with a shape that depends on spatial_shapes values. If such values are unknown at compile time, then all the following computation will be considered data-dependent computation.
class DINOTransformer(nn.Module):
...
def forward(
self,
multi_level_feats: list[torch.Tensor],
...,
**kwargs,
):
...
spatial_shapes: List[Tuple[int, int]] = []
...
for lvl, (feat, ...) in enumerate(zip(multi_level_feats, ...)):
spatial_shapes.append(feat.shape[2:])
...
...
spatial_shapes = torch.tensor(
spatial_shapes, dtype=torch.long, device=feat_flatten.device
)
...
reference_points = self.get_reference_points(spatial_shapes, ...)
@staticmethod
def get_reference_points(spatial_shapes, ...):
...
for lvl, (H, W) in enumerate(spatial_shapes):
ref_y, ref_x = torch.meshgrid(
torch.linspace(0.5, H - 0.5, H, dtype=torch.float32, device=device),
torch.linspace(0.5, W - 0.5, W, dtype=torch.float32, device=device),
)
...
...
However, with a bit of debugging, we can find out that spatial_shapes is actually a constant (given a fixed image resolution), because the feature pyramid (multi_level_feats)’s shapes are known at compile time. So, what’s happening here?
The problem is that constant tensors are still not well supported, as documented in the conversations I had with the PyTorch maintainers (check issue pytorch/pytorch/136642). To summarize the error, PT2E is only folding constant tensors if they are small enough.
There are two ways to solve this issue:
Increasing constant tensor limit with
torch._subclasses.fake_tensor.CONSTANT_NUMEL_LIMIT.Rewriting code to never handle
spatial_shapesas a list of tuples instead of as a tensor. This is because, lists and integers are specialized by default and are well supported.
Although we’ll go with the second option, it’s always better to first try the first one because it’s less intrusive and sometimes is enough.
[x] Increasing constant tensor limit#
try:
torch._subclasses.fake_tensor.CONSTANT_NUMEL_LIMIT = 1000
with torch.no_grad():
ep = torch.export.export(model, inputs)
torch._subclasses.fake_tensor.CONSTANT_NUMEL_LIMIT = 1 # reset to default
except Exception as e:
logging.error(e)
WARNING:py.warnings:/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch/functional.py:539: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3612.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
ERROR:root:Dynamic slicing on data-dependent value is not supported
from user code:
File "/home/dgcnz/development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino.py", line 284, in forward
) = self.transformer(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/home/dgcnz/development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino_transformer.py", line 456, in forward
output_memory, output_proposals = self.gen_encoder_output_proposals(
File "/home/dgcnz/development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino_transformer.py", line 312, in gen_encoder_output_proposals
mask_flatten_ = memory_padding_mask[:, _cur : (_cur + H * W)].view(
Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information
This error is similar to the previous one, and it’s fixable by adding some code to PyTorch’s codebase as I mentioned in this comment from the aforementioned issue. This will be fixed in the future by the PyTorch team with a different approach, so it’s not worth the effort to take this route.
[✓] Rewriting code for non-tensor constants#
The second solution is to rewrite the code to keep spatial_shapes as a list of tuples. This works because PyTorch automatically considers lists and integers as constants.
The disadvantages of this approach are:
It’s a bit more intrusive and error-prone because you need to rewrite all torch operations that use
spatial_shapeswith standard python list operations.We will have to disable the deformable attention cuda kernel because it expects a tensor
spatial_shapes. Maybe the kernel could be rewritten, but TensorRT is already good enough at optimizing the python implementation.
The advantages are:
It’s more robust in comparison with the first solution. We don’t have to rewrite PyTorch’s source code nor wait until they fix the issue.
We can test this, by setting model.transformer.specialize_with_list:
try:
model.transformer.specialize_with_list = True
with torch.no_grad():
ep = torch.export.export(model, inputs)
except Exception as e:
logging.error(e)
ERROR:root:It looks like one of the outputs with type `<class 'detectron2.structures.instances.Instances'>` is not supported or pytree-flattenable.
Exported graphs outputs can only contain the following supported types: [<class 'torch.Tensor'>, <class 'torch.SymInt'>, <class 'torch.SymFloat'>, <class 'torch.SymBool'>, <class 'torch.ScriptObject'>, <class 'NoneType'>, <class 'torch.dtype'>, <class 'bool'>, <class 'str'>, <class 'ellipsis'>, <class 'torch.memory_format'>, <class 'complex'>, <class 'torch.device'>, <class 'torch.layout'>, <class 'int'>, <class 'code'>, <class 'triton.language.core.dtype'>, <class 'bytes'>, <class 'float'>].
If you are using a custom class object, please register a pytree_flatten/unflatten function using `torch.utils._pytree.register_pytree_node` or `torch.export.register_dataclass`.
Nice, new error, that means we’re making progress.
This new error is due to PT2E not knowing how to handle the output of our model, which is a detectron2.structures.instances.Instances object. The way this is solved is by specifying a way to flatten the object, that is, to convert it to a standard container (list, dict, etc) of known flattenable objects. For example, the Boxes class, can be flattened to a tuple of tensors.
There are 2 ways to do this:
PT2E’s suggested method: Register a
pytreenode withflatten_fnandunflatten_fn.Manually do the flattening in the model’s
forwardmethod.
We’ll use the second solution, because torch_tensorrt is not totally compatible with the first one. However, we’ll introduce both, as the first one is more general and could be useful with other backends.
[x] Handling model I/O with PyTree Node Registrations#
def unflatten_detectron2_boxes(values, _):
boxes = object.__new__(detectron2.structures.boxes.Boxes)
boxes.tensor = values[0]
return boxes
def unflatten_detectron2_instances(values, _):
instances = object.__new__(detectron2.structures.instances.Instances)
instances._image_size = values[0]
instances._fields = values[1]
return instances
def flatten_detectron2_instances(x):
return ([x._image_size, x._fields], None)
def flatten_detectron2_boxes(x):
return ([x.tensor], None)
torch.utils._pytree.register_pytree_node(
detectron2.structures.boxes.Boxes,
flatten_fn=flatten_detectron2_boxes,
unflatten_fn=unflatten_detectron2_boxes,
serialized_type_name="detectron2.structures.boxes.Boxes",
)
torch.utils._pytree.register_pytree_node(
detectron2.structures.instances.Instances,
flatten_fn=flatten_detectron2_instances,
unflatten_fn=unflatten_detectron2_instances,
serialized_type_name="detectron2.structures.instances.Instances",
)
try:
ep = torch.export.export(model, inputs)
except Exception as e:
logging.error(e)
Oh nice, it worked, let’s try our luck with tensorrt?
try:
trt_gm = torch_tensorrt.dynamo.compile(ep, inputs)
except Exception as e:
logging.error(e)
ERROR:root:Invalid input type <class 'int'> encountered in the dynamo_compile input parsing. Allowed input types: {torch_tensorrt.Input, torch.Tensor, list, tuple, dict}
This happens because torch_tensorrt expects the model inputs and outputs to be flattened containers (list, dict, tuple) of tensors, and our height, width integers are not supported. Furthermore, our model outputs detectron2.structures.instances.Instances, which poses another problem. Although this is possible, it will involve creating a model wrapper that hardcodes the input/output flattening and specialization. We’ll introduce a more general option next.
[✓] Handling model I/O with TracingAdapter#
We’ve added PT2E support to detectron2.export.flatten.TracingAdapter which does all the flattening for you and also optionally folds the non-tensor inputs as model constants, which applies to our case (height, width are constants).
adapter = TracingAdapter(
model, inputs=inputs, allow_non_tensor=False, specialize_non_tensor=True
)
try:
compilation_successful = True
with torch.no_grad():
ep = torch.export.export(adapter, adapter.flattened_inputs)
trt_gm = torch_tensorrt.dynamo.compile(ep, adapter.flattened_inputs)
except Exception as e:
logging.error(e)
compilation_successful = False
compilation_successful
True
Nice, that worked.
Dealing with image sizes#
In this subsection we’ll add one last change that is necessary to deploying our model: Specializing the input image sizes.
Since, we won’t be using dynamic shapes, we can fix the image size to the camera’s resolution, and disable dynamic images and padding. Although disabling vit’s dynamic inputs is not strictly necessary in the current version of PT2E, it was a source of errors in the previous ones and it’s good practice to do it.
As such, let’s change our image resolution to (512, 512) and put everything together.
img, inputs = load_input_fixed(height=512, width=512, device="cuda")
cfg = LazyConfig.load("projects/dino_dinov2/configs/models/dino_dinov2.py")
cfg.model.backbone.net = LazyCall(TimmBackbone)(
model_name="vit_base_patch14_dinov2.lvd142m",
features_only=True,
out_indices=(-1,),
patch_size=16,
img_size=[512, 512],
dynamic_img_size=False,
dynamic_img_pad=False,
)
cfg.model.transformer.specialize_with_list=True
model = instantiate(OmegaConf.to_object(cfg.model)).eval().cuda()
adapter = TracingAdapter(
model, inputs=inputs, allow_non_tensor=False, specialize_non_tensor=True
)
try:
compilation_successful = True
with torch.no_grad():
ep = torch.export.export(adapter, adapter.flattened_inputs)
trt_gm = torch_tensorrt.dynamo.compile(ep, adapter.flattened_inputs)
except Exception as e:
logging.error(e)
compilation_successful = False
compilation_successful
True
CS2: Compiling ViT+ViTDet+CascadeMaskRCNN#
In this section we’ll cover an unsuccessful case study. As an official detectron2 model, I expected it to be easier to compile, but it turns out it is just not possible without a lot of semantically meaningful rewrites.
Anyway, let’s take what we learned from the previous case study and apply it here.
cfg = LazyConfig.load("detrex/detectron2/projects/ViTDet/configs/COCO/cascade_mask_rcnn_vitdet_b_100ep.py")
model = instantiate(OmegaConf.to_object(cfg.model)).eval().cuda()
img, inputs = load_input_fixed(height=1024, width=1024, device="cuda")
try:
torch._subclasses.fake_tensor.CONSTANT_NUMEL_LIMIT = 1000
compilation_successful = True
adapter = TracingAdapter(
model, inputs=inputs, allow_non_tensor=False, specialize_non_tensor=True
)
with torch.no_grad():
ep = torch.export.export(adapter, adapter.flattened_inputs)
trt_gm = torch_tensorrt.dynamo.compile(ep, adapter.flattened_inputs)
except Exception as e:
logging.error(e)
compilation_successful = False
ERROR:root:Dynamic control flow is not supported at the moment. Please use functorch.experimental.control_flow.cond to explicitly capture the control flow. For more information about this error, see: https://pytorch.org/docs/main/generated/exportdb/index.html#cond-operands
from user code:
File "/home/dgcnz/development/amsterdam/edge/detrex/detectron2/detectron2/export/flatten.py", line 348, in forward
outputs = self.inference_func(self.model, *inputs_orig_format)
File "/home/dgcnz/development/amsterdam/edge/detrex/detectron2/detectron2/export/flatten.py", line 265, in <lambda>
inference_func = lambda model, *inputs: model(*inputs) # noqa
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/home/dgcnz/development/amsterdam/edge/detrex/detectron2/detectron2/modeling/meta_arch/rcnn.py", line 150, in forward
return self.inference(batched_inputs)
File "/home/dgcnz/development/amsterdam/edge/detrex/detectron2/detectron2/modeling/meta_arch/rcnn.py", line 208, in inference
proposals, _ = self.proposal_generator(images, features, None)
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/home/dgcnz/development/amsterdam/edge/detrex/detectron2/detectron2/modeling/proposal_generator/rpn.py", line 477, in forward
proposals = self.predict_proposals(
File "/home/dgcnz/development/amsterdam/edge/detrex/detectron2/detectron2/modeling/proposal_generator/rpn.py", line 503, in predict_proposals
return find_top_rpn_proposals(
File "/home/dgcnz/development/amsterdam/edge/detrex/detectron2/detectron2/modeling/proposal_generator/proposal_utils.py", line 116, in find_top_rpn_proposals
if not valid_mask.all():
Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information
First, we stumble upon a data-dependent expression error on the postprocessing step of the region proposal network. For context, this model first generates ~1000 region proposals that then are fed to the rest of the model to generate the final predictions. In between these steps, there are filtering algorithms to reduce the number of proposals to a more manageable number.
We can look at the relevant code to understand the error:
# 1: filter non-finite boxes
valid_mask = torch.isfinite(boxes.tensor).all(dim=1) & torch.isfinite(scores_per_img)
if not valid_mask.all():
...
boxes = boxes[valid_mask]
scores_per_img = scores_per_img[valid_mask]
lvl = lvl[valid_mask]
...
# 2: filter empty boxes
keep = boxes.nonempty(threshold=min_box_size)
if _is_tracing() or keep.sum().item() != len(boxes):
boxes, scores_per_img, lvl = boxes[keep], scores_per_img[keep], lvl[keep]
# 3: filter based on non-maximum-suppression
keep = batched_nms(boxes.tensor, scores_per_img, lvl, nms_thresh)
...
boxes = boxes[keep]
The issue here is that all of these steps are intrinsically data-dependent: There’s no way to know the final number of boxes at compile time. As such, we’re left with no choice than to skip these steps and hope that the model will still be useful.
There are two other places with similar data-dependent expressions, so we’ll skip them too.
For this, we’ve added the following flags:
detectron2.modeling.proposal_generator.proposal_utils.SKIP_NMS.detectron2.modeling.roi_heads.fast_rcnn.SKIP_FILTER_CONFIDENCEdetectron2.modeling.roi_heads.fast_rcnn.SKIP_NMS.
try:
torch._subclasses.fake_tensor.CONSTANT_NUMEL_LIMIT = 1000
detectron2.modeling.proposal_generator.proposal_utils.SKIP_NMS = True
detectron2.modeling.roi_heads.fast_rcnn.SKIP_NMS = True
detectron2.modeling.roi_heads.fast_rcnn.SKIP_FILTER_CONFIDENCE = True
compilation_successful = True
adapter = TracingAdapter(
model, inputs=inputs, allow_non_tensor=False, specialize_non_tensor=True
)
with torch.no_grad():
ep = torch.export.export(adapter, adapter.flattened_inputs)
trt_gm = torch_tensorrt.dynamo.compile(
ep,
adapter.flattened_inputs,
)
except Exception as e:
logging.error(e, exc_info=True)
compilation_successful = False
ERROR:root:'int' object has no attribute 'size'
Traceback (most recent call last):
File "/tmp/ipykernel_86302/546930148.py", line 12, in <module>
trt_gm = torch_tensorrt.dynamo.compile(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/_compiler.py", line 318, in compile
trt_gm = compile_module(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/_compiler.py", line 366, in compile_module
gm, settings.debug, settings.torch_executed_ops
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/partitioning/common.py", line 195, in get_graph_converter_support
if op_support.is_node_supported(module_dict, node):
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/partitioning/_global_partitioner.py", line 152, in is_node_supported
(node in CONVERTERS or node.op == "get_attr")
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/conversion/_ConverterRegistry.py", line 504, in __contains__
self.__getitem__(key)
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/conversion/_ConverterRegistry.py", line 457, in __getitem__
or not node_has_dynamic_shapes(node)
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/conversion/_ConverterRegistry.py", line 104, in node_has_dynamic_shapes
return _has_dynamic_shapes(node=node)
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/conversion/_ConverterRegistry.py", line 167, in _has_dynamic_shapes
if arg_positions_to_check is None and _is_subnode_dynamic(node):
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/conversion/_ConverterRegistry.py", line 159, in _is_subnode_dynamic
shape = subnode.meta["val"].size()
AttributeError: 'int' object has no attribute 'size'
With a bit of debugging we can discover that the node that is causing this error is a node with target=torch.ops.aten.sym_size.int. This node is supported by TensorRT but some bug is preventing it to be converted correctly.
To see how far we can go, we can bypass this by telling torch_tensorrt to not convert nodes with target torch.ops.aten.sym_size.int.
try:
torch._subclasses.fake_tensor.CONSTANT_NUMEL_LIMIT = 1000
detectron2.modeling.proposal_generator.proposal_utils.SKIP_NMS = True
detectron2.modeling.roi_heads.fast_rcnn.SKIP_NMS = True
detectron2.modeling.roi_heads.fast_rcnn.SKIP_FILTER_CONFIDENCE = True
compilation_successful = True
adapter = TracingAdapter(
model, inputs=inputs, allow_non_tensor=False, specialize_non_tensor=True
)
with torch.no_grad():
ep = torch.export.export(adapter, adapter.flattened_inputs)
trt_gm = torch_tensorrt.dynamo.compile(
ep,
adapter.flattened_inputs,
torch_executed_ops={"torch.ops.aten.sym_size.int"}
)
except Exception as e:
logging.error(e, exc_info=True)
compilation_successful = False
utils.cpp:2468: CHECK(output_shape.size() == rep_vector.size()) failed.
ERROR:torch_tensorrt [TensorRT Conversion Context]:Error Code: 9: Skipping tactic 0x0000000000000000 due to exception No Myelin Error exists
ERROR:torch_tensorrt [TensorRT Conversion Context]:IBuilder::buildSerializedNetwork: Error Code 10: Internal Error (Could not find any implementation for node {ForeignNode[model.backbone.net.blocks.0.norm1/native_layer_norm_weight + model.backbone.net.blocks.0.norm1/native_layer_norm_expand_weight_expand_broadcast...[SHUFFLE]-[aten_ops.permute.default]-[model.backbone.net/permute_223]]}.)
ERROR:root:
Traceback (most recent call last):
File "/tmp/ipykernel_86302/3725039079.py", line 12, in <module>
trt_gm = torch_tensorrt.dynamo.compile(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/_compiler.py", line 318, in compile
trt_gm = compile_module(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/_compiler.py", line 534, in compile_module
submodule,
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/conversion/_conversion.py", line 91, in convert_module
interpreter_result = interpret_module_to_result(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/conversion/_conversion.py", line 70, in interpret_module_to_result
interpreter_result = interpreter.run()
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/conversion/_TRTInterpreter.py", line 639, in run
assert serialized_engine
AssertionError
This new error states that TensorRT can’t find an implementation for a fused node. I’m unsure as to why this happens, but we can fix it by rewriting the code. To pinpoint the source location we can look at the name of the node: ForeignNode[model.backbone.net.blocks.0.norm1/native_layer_norm_weight...] and cross-reference the operators we see with the source code. For example, we know that there’s unsupported code in the detectron2.VisionTransformer blocks because that’s the class of model.backbone.net.blocks[i].
Specifically, the culprit here is the usage of window attention. We can disable it and use only global attention to bypass this error and try to compile again.
cfg = LazyConfig.load("detrex/detectron2/projects/ViTDet/configs/COCO/cascade_mask_rcnn_vitdet_b_100ep.py")
cfg.model.backbone.net.window_block_indexes = []
model = instantiate(OmegaConf.to_object(cfg.model)).eval().cuda()
try:
torch._subclasses.fake_tensor.CONSTANT_NUMEL_LIMIT = 1000
detectron2.modeling.proposal_generator.proposal_utils.SKIP_NMS = True
detectron2.modeling.roi_heads.fast_rcnn.SKIP_NMS = True
detectron2.modeling.roi_heads.fast_rcnn.SKIP_FILTER_CONFIDENCE = True
compilation_successful = True
adapter = TracingAdapter(
model, inputs=inputs, allow_non_tensor=False, specialize_non_tensor=True
)
with torch.no_grad():
ep = torch.export.export(adapter, adapter.flattened_inputs)
trt_gm = torch_tensorrt.dynamo.compile(
ep,
adapter.flattened_inputs,
torch_executed_ops={"torch.ops.aten.sym_size.int"}
)
except Exception as e:
logging.error(e, exc_info=True)
compilation_successful = False
ERROR:root:Cannot convert symbols to int
Traceback (most recent call last):
File "/tmp/ipykernel_86302/3725039079.py", line 12, in <module>
trt_gm = torch_tensorrt.dynamo.compile(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/_compiler.py", line 318, in compile
trt_gm = compile_module(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/_compiler.py", line 506, in compile_module
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/partitioning/common.py", line 91, in construct_submodule_inputs
get_input(input_shape, input_meta.dtype, name=input.name)
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/partitioning/common.py", line 61, in get_input
return construct_dynamic_input(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/partitioning/common.py", line 32, in construct_dynamic_input
min_max_opt = extract_var_range_info(dim)
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch_tensorrt/dynamo/utils.py", line 345, in extract_var_range_info
min_val, max_val, opt_val = int(var_range.lower), int(var_range.upper), int(var_val)
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/sympy/core/expr.py", line 307, in __int__
raise TypeError("Cannot convert symbols to int")
TypeError: Cannot convert symbols to int
No luck.
This is where we stop. This framework-specific bugs are hard to debug and fix as they often are bugs in the compiler itself, so let’s just report it (pytorch/TensorRT/3269). In my experience with the previous case study, these bugs fixed themselves by rewriting the model in order to avoid graph partitioning altogether. We can obtain the unsupported nodes by feeding debug=True to torch_tensorrt.dynamo.compile.
For this model, the unsupported nodes after the removing the filtering steps (non-maximum-suppresion, etc) are:
torch.ops.aten.nonzero.defaulttorch.ops.aten.index.Tensortorch.ops.torchvision.roi_align.defaulttorch.ops.aten.index_put.default
Rewriting the model to avoid these nodes would allow TensorRT to avoid any graph partitioning and thus reduce its dependence on shape analysis. However, we’ve already rewritten essential parts of the model and my guess is that if we continued with more rewrites, the resulting model would not be usable. For example, the weights of window attention do not have the same the same shape as that of the global attention, so the pre-trained model likely already needs finetuning or might not even work anymore.