Adapting the Encoder#
Although we’ve picked our candidate model (dinov2 + ViTDet + DINO) to be general and modular, we’re bound to face some challenges when making them compatible. Let’s try anyways and diagnose the errors as we go. Thankfully, most of the heavylifting has been done by the frameworks where we’ve picked our models from: detrex and detectron2. Make sure to use the forks we’ve provided in our GitHub repository.
Trying to hack our way through#
Show code cell source
import torch
from omegaconf import OmegaConf
from detrex.modeling.backbone import TimmBackbone
from detectron2.config import LazyConfig, instantiate, LazyCall
import logging
logging.basicConfig(level=logging.INFO)
To instantiate the model, we first need to load the base configuration and specify our backbone’s net. We can load dinov2’s ViT-B/14 directly from the timm library. Furthermore, since we want to only use the activations of the last layer as features, we’ll specify out_indices=-1 and features_only. These are common arguments for timm.create_model.
cfg = LazyConfig.load("projects/dino_dinov2/configs/models/dino_dinov2.py")
cfg.model.backbone.net = LazyCall(TimmBackbone)(
model_name="vit_base_patch14_dinov2.lvd142m",
features_only=True,
out_indices=(-1,),
)
Once we’ve setup our model configuration, we can load it on eval mode as follows:
model = instantiate(OmegaConf.to_object(cfg.model)).eval()
Since dinov2’s accepts images of \(518 \times 518\) pixels, we’ll test it with a random image of such size.
x = torch.randn(3, 518, 518)
try:
model([{"image": x, "height": 518, "width": 518}])
except Exception as e:
logging.exception(e)
ERROR:root:list index out of range
Traceback (most recent call last):
File "/tmp/ipykernel_3623/2513710352.py", line 3, in <module>
model([{"image": x, "height": 518, "width": 518}])
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/home/dgcnz/development/amsterdam/edge/projects/dino_dinov2/modeling/exportable/dino.py", line 232, in forward
features: Dict[str, torch.Tensor] = self.backbone(
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/dgcnz/.conda/envs/cu124/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/home/dgcnz/development/amsterdam/edge/detrex/detrex/modeling/backbone/eva.py", line 594, in forward
top_block_in_feature = results[self._out_features.index(self.top_block.in_feature)]
IndexError: list index out of range
Oh. We’ve encountered an error, and it’s not a fun one. In fact, it is so cryptic that diagnosing it by code is not feasible in a short time. The only hint here is that it has to do with the backbone and the feature pyramid. The best course of action here is to not hack our way out of it, but review the theory behind ViTDet and cross-check with the code. So let’s do that.
VitDet 101#
To summarize, ViTDet is a module that makes ViTs compatible with state-of-the-art detector heads (Cascade Mask-RCNN, DINO, DETR), by generating a feature pyramid from the ViT’s last layer activations (see Figure 5).
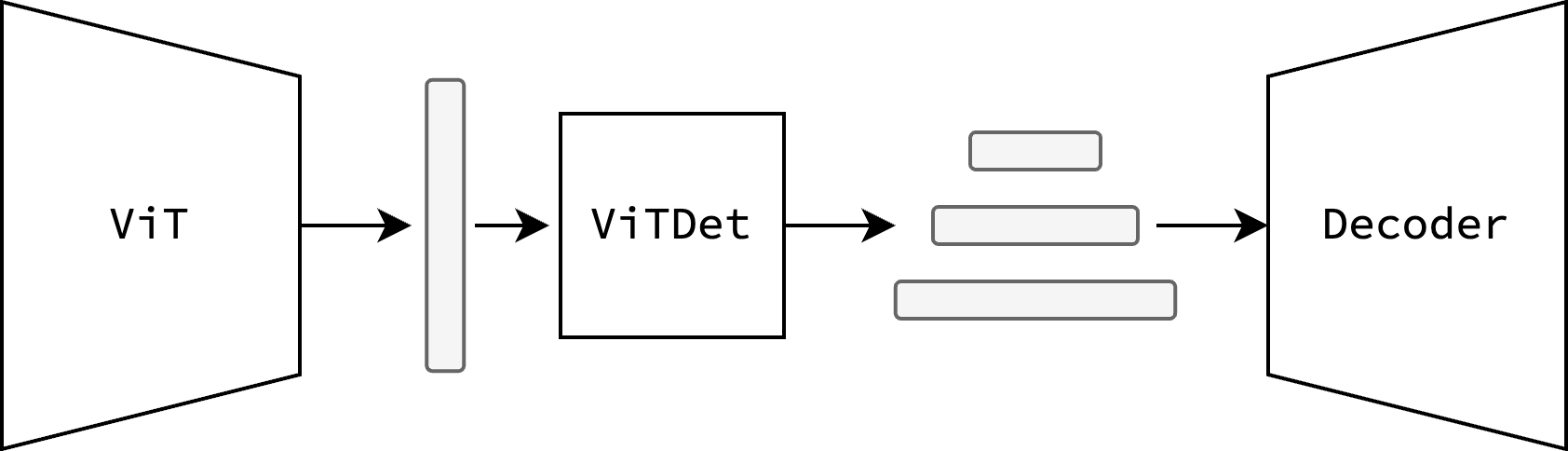
Fig. 5 ViT’s features are fed to ViTDet, which then generates a feature pyramid for the detector head.#
The reason why feature pyramids are important is twofold:
Object Detection is sensitive to scale, and having features at different scales helps the model detect objects of different sizes.
ConvNets (the historical de-facto vision model) tend to be organized as a series of blocks that downsample the input, which is why many detectors have been designed to take advantage of this inherent hierarchy of features. Some of these variations can be seen in Figure 6.
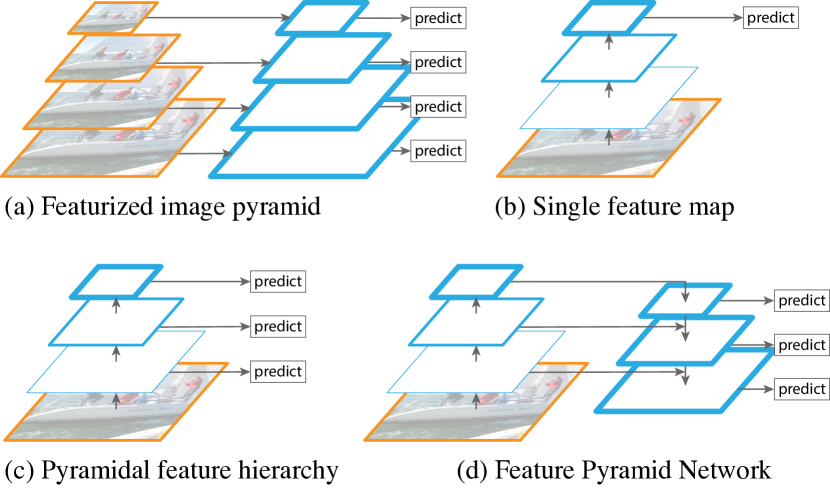
ViTs, on the other hand, have a fixed-sized feature map, and thus don’t fit well in this framework. As such, ViTDet helps generating a feature pyramid by applying a series of strided convolutions/de-convolutions (see Figure 7) and thus upsampling/downsampling at different scales (powers of 2).
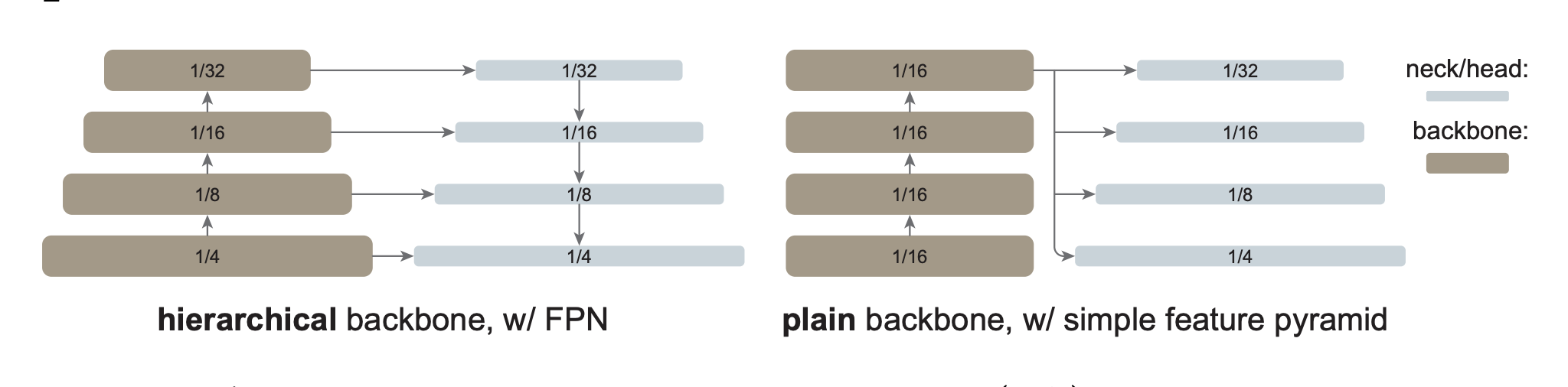
Fig. 7 Feature Pyramids with Hierarchical Backbones (CNNs) and Plain Backbones (ViTs) [LMGH22]#
Hold on, powers of 2? That reminds me of something funny about dinov2. It’s patch size is 14. Although this technically shouldn’t be a problem with scales \((2, 1, 0.5)\), it definitely would break with a a scale of \(0.25\). However, I’ll spare you the details of fixing such a bug because the paper [LMGH22] solves a similar case in Appendix A.2 by ignoring this edge case and just interpolating the patch embedding filters from \(14 \times 14\) to \(16 \times 16\).
Sadly, I couldn’t find any implementation of such interpolation in the offical ViTDet codebase. However, EVA [FSW+24] also uses a patch size of 14, and they’ve implemented a similar interpolation in their codebase. Furthermore, patch interpolation is a standard feature of timm ViTs, so we can cross-check with their implementation. The latter would be ideal, as it be less annoying to deal with.
To test this equivalence, we can load a pre-trained ViT-B/14 model from timm and compare its activation distribution with both interpolation methods and one uninitialized ViT-B/16 model. If the distributions are similar, we can safely assume that the interpolation method is sound. A plot of this can be found in Figure 8.
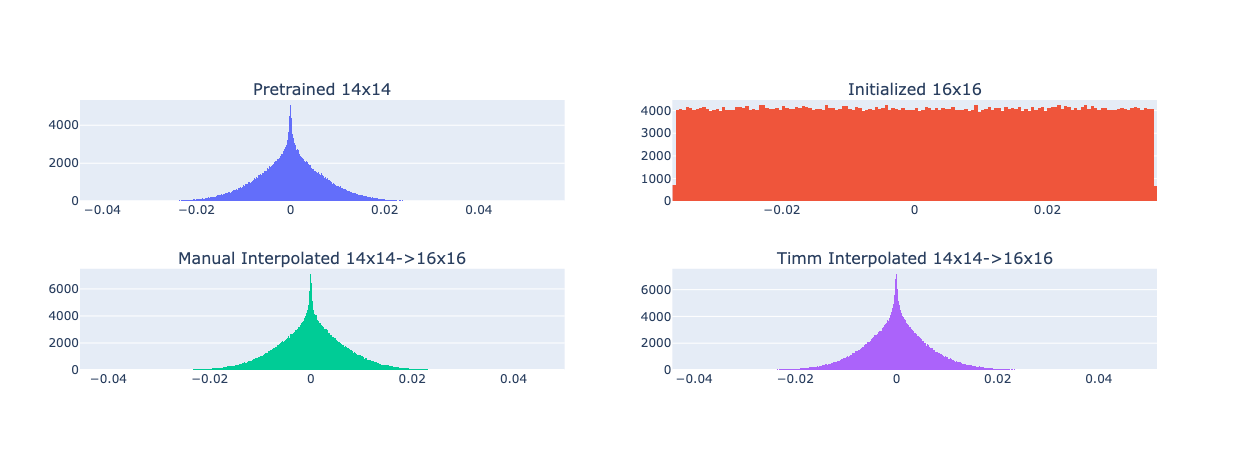
Fig. 8 Comparison of Activation Distributions of ViT-B/14, ViT-B/16, and Interpolated ViT-B/14 (timm and eva).#
So, that seems to work. Let’s try it.
cfg.model.backbone.net = LazyCall(TimmBackbone)(
model_name="vit_base_patch14_dinov2.lvd142m",
features_only=True,
out_indices=(-1,),
patch_size=16,
)
model = instantiate(OmegaConf.to_object(cfg.model)).eval()
x = torch.randn(3, 518, 518)
y = model([{"image": x, "height": 518, "width": 518}])
print(type(y[0]["instances"]))
<class 'detectron2.structures.instances.Instances'>
Nice, that worked.